Hi 👋🏻
Have you ever noticed that when you ask an AI chatbot or search system a question, the answer often covers angles you didn’t explicitly ask about?
That’s not it being creative. It’s a mechanism asking dozens of questions on your behalf — questions you never typed, shaped by what it knows about you (emphasis on you, based on memory settings and past preferences) and the topic you're exploring.
The query fan-out mechanism is without doubt the single most significant expansion of how searching works in recent years.
I recently published a deep-dive into how AI search platforms expand queries for iPullRank, and I want to share the core concepts with you here — condensed and contextualised for the MLforSEO community. Let’s get into it.
What Is Query Fan-Out?
Query fan-out is the map of every related question an AI system generates or infers from a single user query. It shows the full range of angles, subtopics, and follow-up intents the model considers relevant. That spread determines how much of your content gets pulled into answers across AI Overviews, AI Mode, ChatGPT, Gemini, and Perplexity.
You’ll remember from our discussion on query augmentations in #006 that traditional search systems already did something similar — they added related terms, triggered SERP features like People Also Ask, and used session context to refine results. But query fan-out goes a critical step further: it expands a single query into multiple subqueries, fires them in parallel, retrieves passages from across the web, and then synthesises everything into one response.
All of this with deep adaptation to individual users, too.
Think of the difference this way: traditional search refined your query. AI search researches it.
What this means for SEOs, a translation: Traditional search personalizes rankings. AI search personalize the questions asked on the user’s behalf.
How the Mechanism Works
Google’s query fan-out mechanism is described in detail in the several patents. Here’s what happens when you submit a query:
- Decomposition. The system breaks your query into subtopics and facets. NLP algorithms analyse complexity and determine intent. A simple factual query like “capital of Germany” gets minimal decomposition. A complex query like “Bluetooth headphones with comfortable over-ear design and long-lasting battery for runners” triggers extensive fan-out.
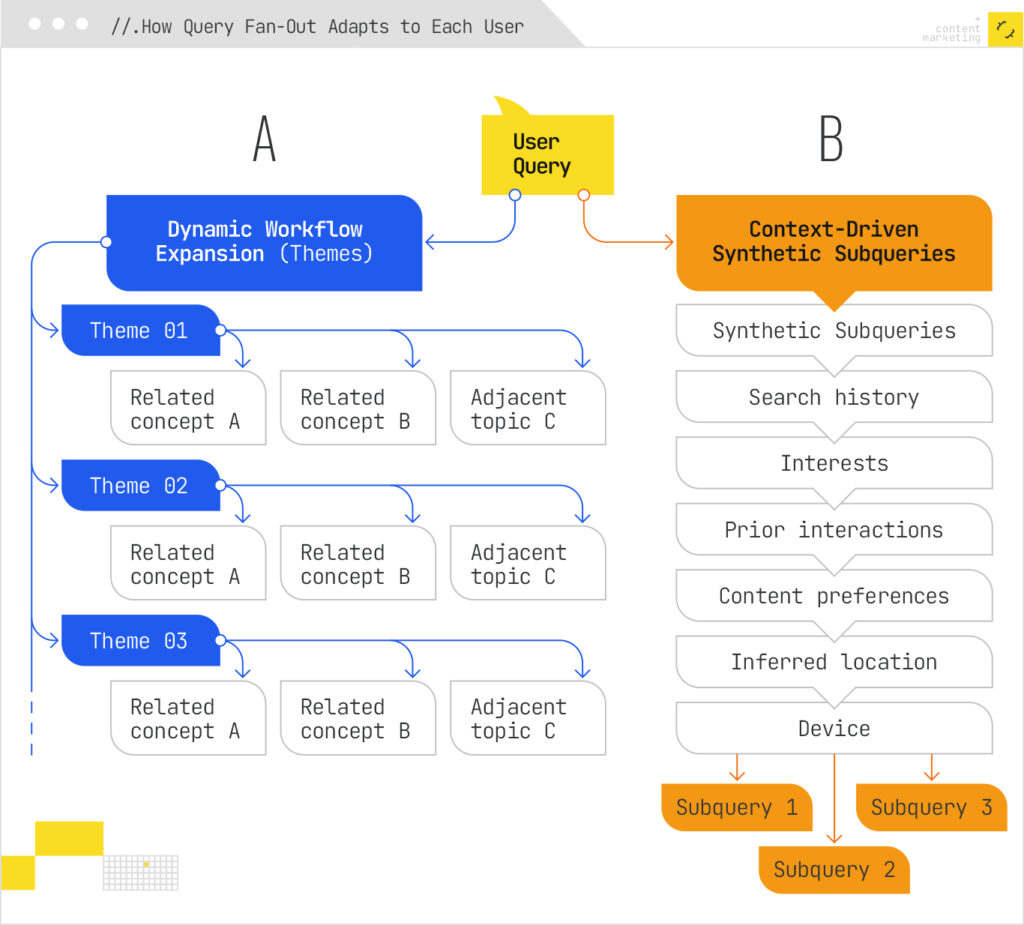
- Synthetic query generation. The system doesn’t just rephrase your question. Trained generative models produce eight distinct types of query variants: equivalent queries (alternative phrasing), follow-up queries (logical next questions), generalisation queries (broader versions), specification queries (more detailed versions), canonicalisation queries (standardised phrasing), language translation queries, entailment queries (logically implied questions), and clarification queries.
- Parallel retrieval. All these subqueries fire simultaneously across the live web, knowledge graphs, and specialised databases like Shopping Graph. The system retrieves passages — not full pages — from multiple documents, building a rich portfolio of evidence.
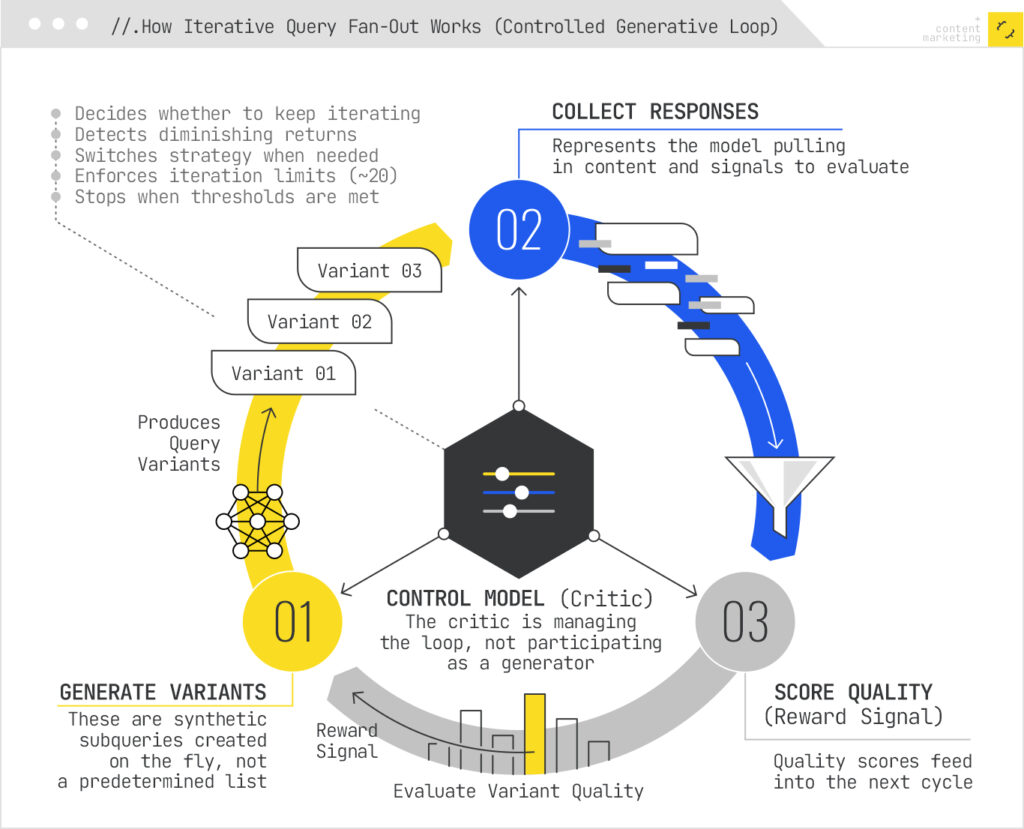
- Iterative refinement. A control model (a “Critic”) evaluates the quality of retrieved results and decides whether to continue searching or stop. This reinforcement learning loop means the system gets progressively better at finding the right evidence for each query.
- Grounded synthesis. The LLM uses the retrieved passages to compose a cited, factual response. This is where RAG (Retrieval-Augmented Generation) meets fan-out — the parallel subqueries strengthen the retrieval step, giving the LLM richer material to ground its answer in.
Every Major AI Search Platform Uses This
This isn’t a Google-only mechanism. Every major AI search platform implements some version of it, though they frame it differently:
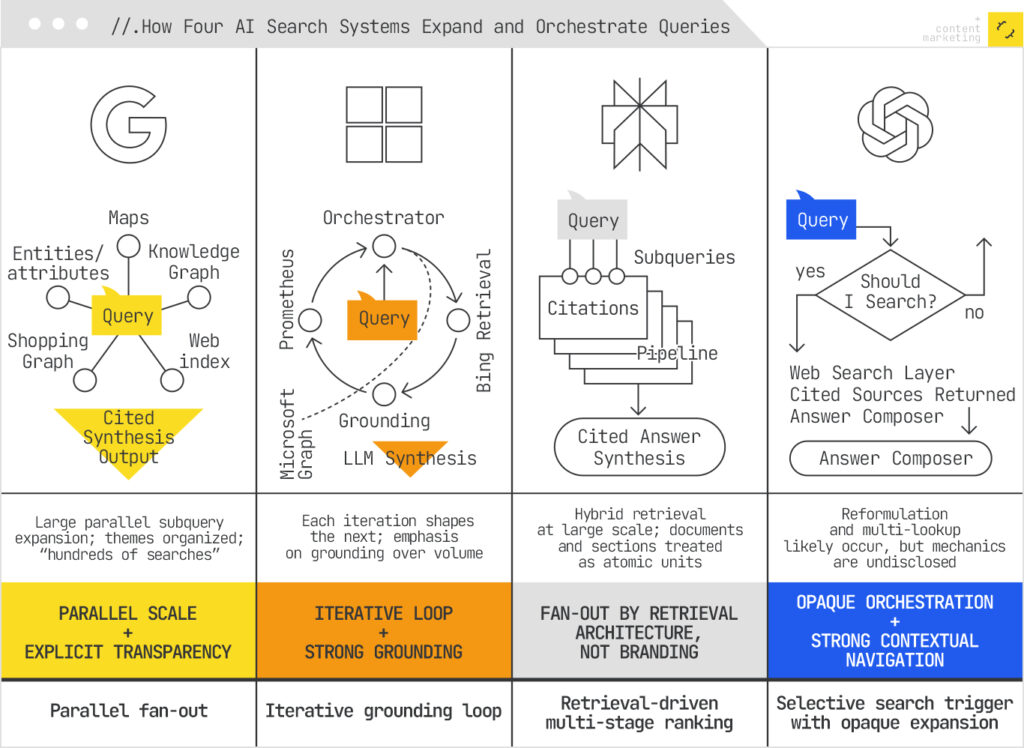
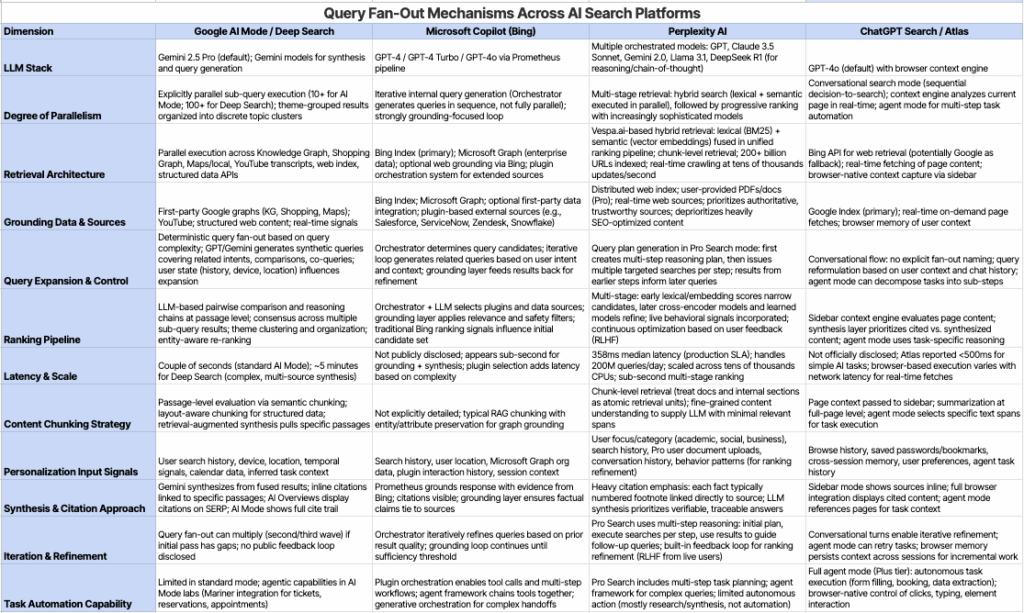
- Google AI Mode & Deep Search: Explicit, large-scale parallel fan-out across the web, Knowledge Graph, Shopping Graph, and Maps. Google has named this mechanism publicly and documented it across several patents.
- Perplexity: Performs hybrid retrieval with multi-stage ranking on a swarm of queries. Processing 200 million queries daily, Perplexity treats documents and sections as atomic retrieval units. You can actually see the subqueries firing in their UI.
- Microsoft Copilot: Uses Bing’s Orchestrator to route queries through an iterative, graph-grounded pipeline. Each result informs the next, creating a grounding loop. For enterprise users, this extends to Microsoft Graph (your organisational data).
- ChatGPT Search: Strongly suggests query reformulation and multiple lookups, though OpenAI hasn’t published details about orchestration or subquery generation. Less transparent, but the behaviour is clearly fan-out.
Despite the different framing, all platforms decompose queries into multiple subqueries and synthesise the results. Your content needs to be discoverable not just by the literal query, but by the universe of related, themed, and contextual subqueries that any of these systems might generate.
Deep dive into the differences with this resource ⬇️
How Fan-Out Can Skew Intent
Here’s where it gets really interesting — and where the connection to personalisation (#008) becomes critical. Despite being designed to precisely address user needs, the fan-out mechanism can actually skew intent in several ways:
Semantic drift through generative expansion. When the system generates follow-up, generalisation, and entailment queries, it explores adjacent concepts using high-dimensional vector space and knowledge graph linkages. In traditional search, these expansions appeared as suggestions the user could choose to explore (People Also Ask, Related Searches). In AI search, the system fires them automatically and weaves the results into the response. The user doesn’t choose — the system decides for them.
Deep personalisation injects historical bias. The subqueries aren’t generated from the query alone. They’re heavily shaped by user attributes: past search behaviour, location, device, temporal signals, even calendar data and active applications. As I explored in my iPullRank article on how AI search personalises fan-out queries using memory and context, two users typing the identical query get different fan-out expansions. Different context → different fan-out → different data retrieved → different answer. Same input, entirely different experience.
Two-point transformation misses intent shifts. The system infers intent from historical behaviour using what’s called a two-point transformation — it looks at past behaviour and current query, but neglects the intermediate transitions that characterise how users actually refine their intent. If someone searched for marathon shoes on Monday and low-impact cardio on Friday (because of an injury), the system may treat both as variations of the same intent rather than recognising a fundamental shift.
Iterative expansion can diverge too far. Some systems don’t just execute a single burst of subqueries. They use iterative expansion — extracting enrichment terms (entities, concepts) from initial results and generating follow-up queries from those. If this continues without converging back toward the original intent, later-stage queries drift toward tangentially related content. You start with “charging infrastructure” and end up retrieving documents about battery production supply chains in China.
Explore my deep dive on this in the complete article on iPullRank's blog
Interested in measuring semantic drift? Try this tool. ✨
The Entity Connection
If you’ve been with this newsletter since #004 (entities as the backbone of AI search), here’s where it all comes together. Fan-out is deeply entity-driven. As I covered in an earlier article on how AI search platforms leverage entity recognition:
- LLMs detect entities in the user query and use entity relationships and topical proximity to drive fan-out and generate synthetic queries.
- Entity-based reformulations crosswalk references to broader or narrower equivalents using Knowledge Graph anchors — for example, “SUV” could be expanded to specific models like “Model Y” or “Volkswagen ID.4.”
- Retrieval constraints enforce hard/soft filters by entity type and specific IDs, admitting only passages that resolve to the target entity.
- Chunk boundaries often align with the EAV model (entities, attributes, variables), so content structured around clear entity–attribute relationships is more cleanly retrievable.
This means that the entity foundations in SEO aren’t just theoretical — they’re the operating system that fan-out runs on, but as you probably know by now - so does the entire web or traditional SEO since the 2010s.
Clear entities with stable IDs, precise attributes, and verifiable facts give the fan-out system anchors to work with instead of ambiguity to drift from. They are also the backbone of reputable, sustainable, scalable SEO strategies.
What This Means for Your Content Strategy
Your content doesn’t need to 'match' the user’s exact query anymore. It needs to appear and show relevance for multiple synthetic queries the system generates from it.
Here’s what that looks like in practice:
- Make your content atomic and extractable. Write semantically complete passages where each paragraph can stand on its own as an answer to a specific subquery. Start passages with the canonical entity name and verifiable facts. LLMs retrieve passages, not pages.
- Build for intent transitions, not single intents. Fan-out generates subqueries across the user journey — research, comparison, decision, implementation. Create content (or rather - content systems and libraries) that cover these transitions explicitly, so your pages stay in the retrieval set as the fan-out explores different facets.
- Use structured data to anchor entities. Schema markup with persistent @ids, sameAs links to Wikidata or Knowledge Graph IDs, and explicit entity relationships help the system retrieve your content for the right entity-based subqueries. This isn’t decorative — it’s the mechanism that power both traditional and AI search, winning the former is often a comfortable position in the latter.
- Shift measurement from rankings to citations. Stop asking “What’s my rank?” Start asking “Am I being cited in AI-generated answers? For which entities and attributes? In which reasoning chains?” These metrics are harder to track, but they’re what matters when ranking as we knew it is no longer the game.
- Think semantic coherence, not keyword targeting. You can’t rely on ranking for specific queries when the query itself expands and personalises dynamically. Instead, build your content’s semantic coherence and retrievability across multiple expansion paths. This is what my iPullRank article calls building an “ontological core” — a foundation that allows LLMs to reason across your entities regardless of how the query is decomposed.
Learn more on this topic in our Featured Courses 🌟
The Semantic AI-powered Keyword Research course now includes a dedicated module on synthetic queries and query fan-out in AI search systems — covering how to distinguish between synthetic and user-initiated queries, how query fan-out works in AI Mode and beyond, and how to adapt your keyword research for this new paradigm.
The AI Search & LLMs: Entity SEO and Knowledge Graph Strategies for Brands course by Beatrice Gamba covers the entity foundations that make your content fan-out-compatible — from entity auditing to schema building to knowledge graph integration.
135+ forward-thinking marketers are already taking our courses 💜
Further Reading 📚
For the full deep-dive with patent references, platform-by-platform breakdowns, and detailed architectural analysis:
Community discussion 🌟
I recently asked the MLforSEO community about their favourite tools for query fan-out generation and synthetic queries. Here are the top tools you should consider adding to your arsenal:
What role do query fan-outs and synthetic queries currently play in your keyword research and content strategy processes? - join the discussion on Slack.
(If you haven't already...) Join 750+ AI/ML-interested marketers on our Slack community to stay up to date with discussions on AI/ML automation in SEO and marketing.
Happy learning! ✨
Lazarina